-
Deep Speech & Deep Speech2 간단 리뷰논문 리뷰 2022. 1. 15. 23:28
[1412.5567] Deep Speech: Scaling up end-to-end speech recognition (arxiv.org)
Deep Speech: Scaling up end-to-end speech recognition
We present a state-of-the-art speech recognition system developed using end-to-end deep learning. Our architecture is significantly simpler than traditional speech systems, which rely on laboriously engineered processing pipelines; these traditional system
arxiv.org
Deep Speech 2 : End-to-End Speech Recognition in English and Mandarin (mlr.press)
Deep Speech 2 : End-to-End Speech Recognition in English and Mandarin
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech–two vastly different languages. Because it replaces entire pipelines of hand-eng...
proceedings.mlr.press
2014, 2016년도에 발표된 baidu의 음성 인식 논문인 Deep speech & Deep speech 2에 대한 논문을 리뷰하겠습니다.
지난 LAS 논문에서 처럼 Deep speech또한 end-to-end ASR 시스템의 시초 격이라 볼 수 있다.
기존에 DNN-HMM으로 대표되는 ASR pipeline의 복잡성을 출이기 위해 end-to-end 음성인식 시스템을 고안했다.
RNN을 이용하여 음성 인식 시스템을 만들고 싶었으나 당시 하드웨어의 한계 때문에 Deep Speech1 의 모델은 현재를 기준으로 매우 간단한 형태를 띄고 있다.
총 5개의 layer로 구성이 되어 있으며 1~3번째 layer은 단순한 MLP 형태, 4번째 layer은 bidirectional RNN 이고, 마지막 5번째 layer도 MLP 로 이루어지고, softmax 계층을 거쳐 나올 문자의 확률을 추출하는 모델이다.

Deep Speech1 model architecture 모델의 인풋은 power spectorgram 이고, output은 문자열이다. (a,b,c,d, ... , z, space, apostrophe, blank)
4번째 RNN층은 흔히 seq-2-seq 에서 많이 사용하는 LSTM이 아닌 GRU 를 이용하였다.
모델의 목적함수는 CTC loss 를 이용했는데, 이를 다음 포스팅에 더 자세히 알아보는 시간을 가지도록 하겠다.
이 모델의 성능을 높이기 위하여 몇가지 방법을 사용했는데, 먼저 5~10% 의 dropout을 적용하여 모델이 오버피팅 되는것을 막았다. 또한 그림에서 볼 수 있듯 input spectrogram에 앞 또는 뒤에 랜덤으로 5ms의 jittering을 주었다.
Language 모델을 따로 사용했는데, RNN output만의 결과보다 Language model 과 함께 decode 한 결과가 더 잘 맞았다. 적용하는 식은 다음과 같다.

이때 당시만 해도 하드웨어가 부족하던 시절이었는지 Data parallelism 과 model parallelism을 이용하여 멀티 GPU 환경에서 학습을 했다.

논문이 발표되고 2년 뒤에 후속 논문이 발표 되었다. 기존 Deep Speech와 거의 비슷한 아키텍쳐에 더 깊은 계층을 쌓은듯한 모델이다. 그리고 MLP 대신 CNN 계층을 사용한 것이 특징이다.
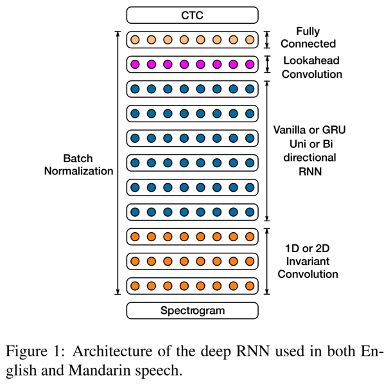
Deep Speech2 model architecture input 단을 보면 1D 또는 2D convolutional layer을 사용하여 time 또는 time&frequency 축으로 convolution 연산을 하였다. 그리고, RNN계층이 더 깊어졌다. 매 RNN 층 다음에는 Lookahead convolution layer가 자리하고 있는데 이는 RNN 의 몇 time stamp 다음 output 까지 같이 계산한다.

lookahead convolution arhitecture with future context size of 2 Deep speech2와 다른점 중 하나는 Batch Normalization을 사용한 점이다. RNN에서는 sequence-wize BN을 적용하니 효과가 더 좋아서 12%의 성능 향상이 있었다고 한다.
이 모델은 처음에 학습이 불안정하여 잘 학습시키기 위해 SortaGrad 방법을 사용했다고 한다. 첫 epoch때 Spectrogram의 길이 순서로 정렬하여 길이가 짧은 Spectrogram 부터 학습을 하는 방법이다. 이후의 epoch부터는 랜덤 순서로 mini batch를 만들어 학습을 한다.

'논문 리뷰' 카테고리의 다른 글
TRPO: Trust Region Policy Optimization (0) 2022.05.11 MUTE: Multitask Training with Text Data for End-to-End Speech Recognition (0) 2022.05.11 Listen, Attend and spell (0) 2022.01.01 VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture 리뷰 (0) 2021.10.13 WaveGlow: A Flow-based Generative Network for Speech Synthesis 리뷰 (0) 2021.10.13