-
MUTE: Multitask Training with Text Data for End-to-End Speech Recognition논문 리뷰 2022. 5. 11. 12:43
[2010.14318] Multitask Training with Text Data for End-to-End Speech Recognition (arxiv.org)
Multitask Training with Text Data for End-to-End Speech Recognition
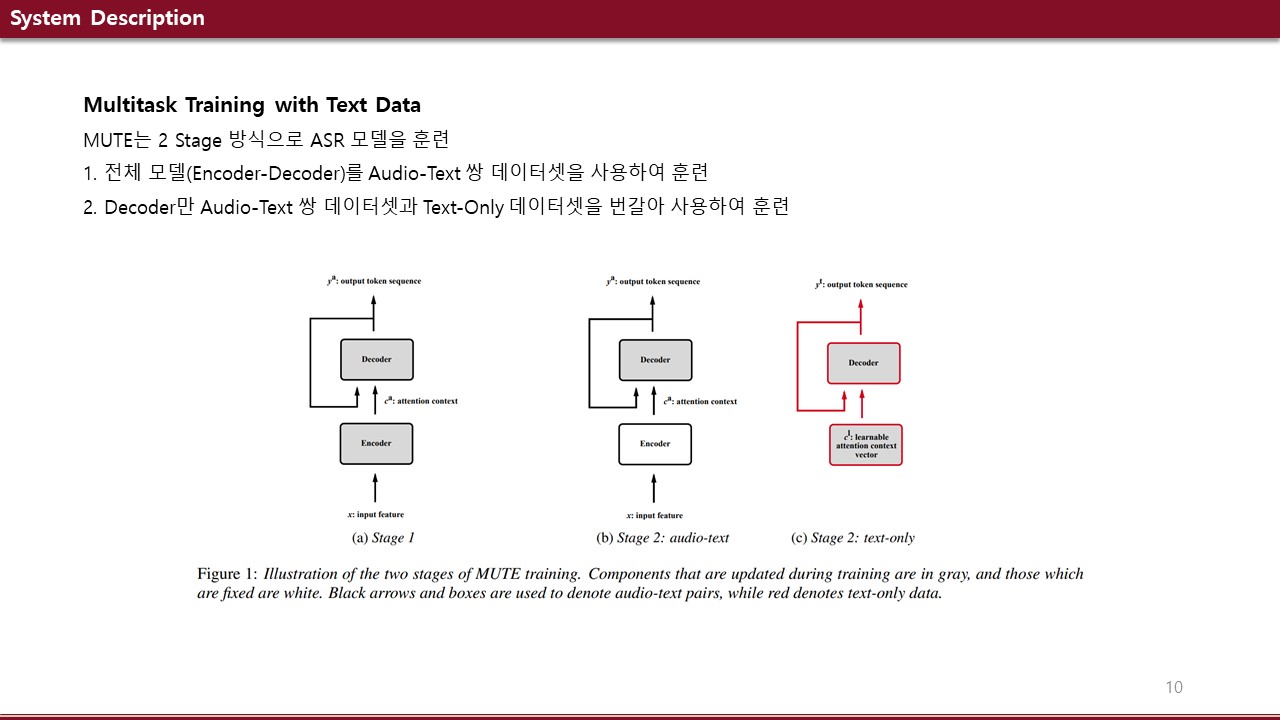
We propose a multitask training method for attention-based end-to-end speech recognition models. We regularize the decoder in a listen, attend, and spell model by multitask training it on both audio-text and text-only data. Trained on the 100-hour subset o
arxiv.org




















'논문 리뷰' 카테고리의 다른 글
Cycle GAN VC 3 and Mask Cycle GAN VC (0) 2022.05.11 TRPO: Trust Region Policy Optimization (0) 2022.05.11 Deep Speech & Deep Speech2 간단 리뷰 (0) 2022.01.15 Listen, Attend and spell (0) 2022.01.01 VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture 리뷰 (0) 2021.10.13