-
고성능 파이썬 Chapter 09 - Multiprocessing 모듈 part 1 (~9.4절)STUDY/고성능 파이썬 2025. 1. 12. 15:47
들어가며
파이썬은 기본적으로 1개의 CPU 코어만을 사용하도록 되어 있어서 이번 과를 통해 더욱 효율적으로 프로그램을 돌릴 수 있도록 해주는 방법을 배울 수 있기를 바란다.
이 장에서 배울 내용
- multiprocessing 모듈이 제공하는 기능
- 프로세스와 스레드의 차이
- 프로세스 풀의 적절한 크기를 정하는 방법
- 작업 처리를 위해 영속적이지 않은 큐를 사용하는 방법
- 프로세스 간 통신의 비용과 효과
- 여러 CPU를 사용해 numpy 데이터를 처리하는 방법
- joblib을 사용해 병렬화하고 캐시된 과학 계산 작업을 단순화하는 방법
- 데이터 손실을 막기 위해 락을 사용해야 하는 이유
파이썬 프로그램을 실행시키면 기본적으로 1개의 CPU가 모든 동작을 수행한다. 하지만 2000년대 후반 이후 거의 모든 CPU는 멀티 코어를 지원하면서 multiprocessing을 이용하면 원하는 작업을 더욱 빠르게 수행할 수 있다.
문제를 여러 CPU로 병렬화 한다면 n 코어 시스템에서 최대 n배의 성능 향상을 기대할 수 있다.
그러나 RAM 사용, 통신 오버헤드 등으로 인해 n배만큼 빨라지기는 매우 힘들고, 오히려 통신 오버헤드 때문에 오히려 느려질 수도 있다.멀티프로세싱을 하면 크게 multiprocessing 모듈, joblib 모듈을 이용하면 된다.
multiprocessing 모듈로 처리할 수 있는 작업은
* CPU bound 작업을 process나 pool 객체를 사용해 병렬화
* dummy 모듈을 사용해서 I/O bound 작업을 스레드를 사용하는 pool로 병렬화
* Queue를 통해 pickling한 결과를 공유
* 병렬화한 작업자 사이에서 바이트, 원시 데이터 타입, 사전, 리스트 등의 상태를 공유
등의 작업이다.
프로세스(Process): 현재 프로세스를 fork 한 복사본. 새로운 pid 부여
풀(Pool): Process나 Threading.Thread API를 감싸서 사용하기 편한 작업자 풀로 만든다.
큐(Queue): 여러 생산자와 소비자가 사용할 수 있음
파이프(Pipe): 두 프로세스 사이의 단/양방향 통신 채널
관리자(Manager): 프로세스간 파이썬 객체를 공유하는 고수준의 관리된 인터페이스
ctypes: 프로세스를 포크한 다음 여러 프로세스가 원시 데이터 타입을 공유
동기화 도구: 락, 세마포어 등
몬테카를로 방식을 사용해 원주율 추정
1x1 격자 위에 random으로 점을 찍어 사분원 위의 값인지를 확인하여 π의 근사치를 구해보는 실습을 해보자.

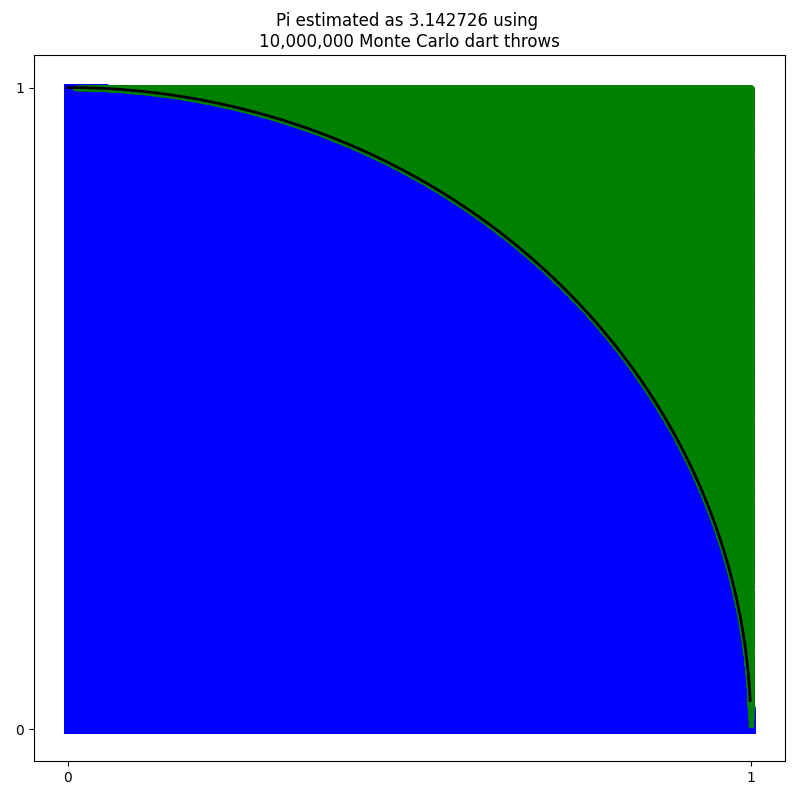
기본은 이 코드에 따라 1만개의 점을 샘플링한다.(좌) 1000만개의 샘플을 가지고 추정하면 이때 5초 정도 소요되었다.(우)
1억개의 샘플링을 하면 40초 정도 소요되었다. 예제 코드

m2 의 코어수는 8개라 8코어를 이용하여 parallel 하게 수행하면 다음과 같은 결과를 얻는다. 예제 코드

thread 사용 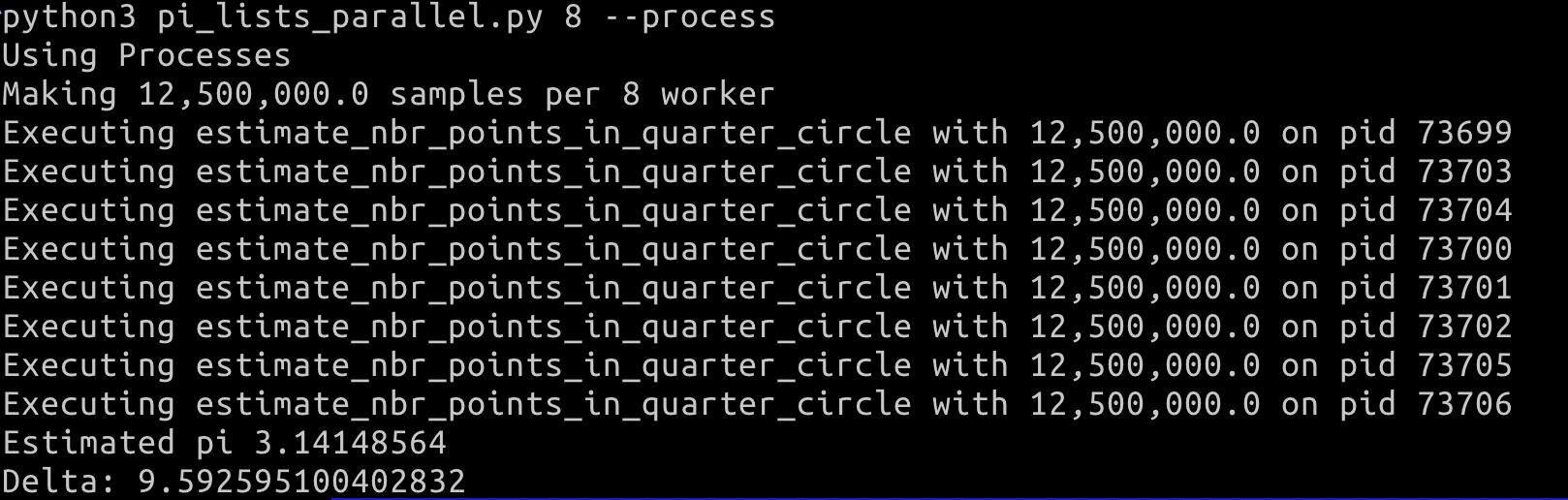
process 사용 위의 수행 결과는 from multiprocessing.dummy import Pool을 이용했고,
아래 수행 결과는 Pool을 from multiprocessing import Pool을 이용했다.
위의 멀티 스레드를 이용하여 수행한 방식은 I/O bound 프로그램에 적합한 방식으로, 이번 예제에서는 시간적으로 이득을 얻지 못하였다.반면에 멀티 프로세싱을 이용한 방식은 CPU bound 프로그램에 적합하여 4배 정도의 속도를 얻었다.
joblib을 이용한 실습 결과는 다음과 같다. 예제 코드



joblib은 cache도 지원한다. 수행 결과를 하드디스크에 저장하는 역할도 하여 이전 결과를 다시 가져와서 쓸 수도 있다. cache를 잘 하고, 원하는 결과를 가져올 수 있게 함수에 idx를 매개변수로 추가했다. (그렇지 않으면 각 함수의 결과를불러올때 동일한 값을 불러와지게 되어 mote carlo하게 동작하지 않음)
난수 발생도 병렬 프로세스에서 중요한 과제이다. 일반적으로는 numpy나 python의 난수 발생기의 구현으로 충분할 것이다.
연산 또한 list 대신 numpy를 이용한다면 더욱 빠르게 수행할 수 있을 것이다. 예제 코드
유사한 예제로 소수인지 판별에 대해서 생각하자. 유명한 에라토스테네스의 체를 이용하면 된다.
이번 예제에서는 프로세스간의 통신이 필요한 작업이 있다.
이번 예제에서는 부하를 균등화 하는 방법을 살펴볼 것이다.
예제에서는 하나의 프로세스에 chunksize 갯수의 숫자에 대한 소수 판별을 실시한다.
chunk size가 작으면 프로세스가 많아져서 함수 생성, return 등에 많은 오버헤드가 발생.
극단적으로 chunk size가 커서 프로세서가 4개일때 프로세스가 10개라고 하면 처음 2번은 동시에 4개의 프로세서가 작업을 하지만, 이후 2개의 프로세서만 일을 하게 되면서 작업 효율이 떨어진다.
따라서 적정한 프로세스는 프로세서의 수와 비례하게 설정한다. (전체 작업 % 코어 수)
또한, 소수 판별의 문제는 소수의 sequence가 규칙적이지 않기 때문에 작업 순서를 임의로 섞었을 때 작업의 효율이 2%가량 늘어났다.
작업 큐는 작업들 사이에 객체를 pickling하여 프로세스간 전송하기 위해 사용한다.
'STUDY > 고성능 파이썬' 카테고리의 다른 글
고성능 파이썬 Chapter 10 - 클러스터와 작업 큐 (0) 2025.02.02 고성능 파이썬 Chapter 09 - Multiprocessing 모듈 part 2 (9.5절~) (0) 2025.01.19 고성능 파이썬 Chapter 08 - 비동기 I/O (1) 2025.01.05 고성능 파이썬 Chapter 7 실습 (0) 2024.12.30 고성능 파이썬 Chapter 07 - C 언어로 컴파일하기 (0) 2024.12.22