-
고성능 파이썬 Chapter 1 - 고성능 파이썬 이해하기STUDY/고성능 파이썬 2024. 11. 23. 16:36
들어가며
회사에서 파이썬 프로그래밍을 하면서 생산성은 올라갔지만, 코드를 제대로 작성하고 있는지에 대한 많은 의심이 들었다. 일단은 "동작 하는" 코드를 만드는게 우선이었기 때문에 작성한 코드에 최적화를 할 수 있는 요소들이 많이 있었을 것이다. 좋은 코드, 성능 최적화에 대한 갈망이 마음 속에 있던 중 네이버에서 주최한 "DAN 24" 의 당신의 Python 모델이 이븐하게 추론하지 못하는 이유 [CPU 추론/모델서빙 Python 딥다이브]를 보고 파이썬에 Deep dive를 해야겠다는 생각이 들어서 Micha Gorelick, Ian Ozsvald의 저서 "고성능 파이썬"을 공부하고자 한다.
1.1 기본 컴퓨터 시스템
컴퓨터 시스템은 연산장치(CPU, GPU), 저장장치(Cache, 주기억장치, 보조기억장치 등), 통신 계층(System Bus, 네트워크 등) 으로 나눌 수 있다.
1.1.1 연산장치
연산장치의 속도에 대한 지표는 "한 사이클에 처리할 수 있는 연산의 개수(IPC)"와 "1초에 처리할 수 있는 사이클의 횟수(CPS, cpu 클클럭과 비례)"로 측정한다. 두 지표 다 높은 CPU를 만들면 좋겠지만, 이는 현실적으로 어려워서 IPC가 높으면 CPS가 낮고, CPS가 낮으면 IPC가 높다. 이를 보완하기 위해 CPU 제조사들은 "멀티 쓰레드" CPU를 개발하였고, 따라서 멀티 쓰레딩 프로그래밍을 잘 하는것이 프로그램의 속도를 높일 수 있는 관건이다. 하지만, 무작정 멀티 쓰레딩을 이용한다고 했을때 성능이 계속 오르지 않는다.(암달의 법칙) 또한, 파이썬에서는 Global Interpreter Lock(GIL)로 인하여 한 번에 명령 하나만 실행하도록 강제한다. 따라서 파이썬을 이용하여 멀티 쓰레드 프로그램을 작성 하려면 이를 회피할 수 있는 라이브러리(multiprocessing 모듈, Numpy) 등을 이용해야 한다.
1.1.2 저장장치
저장장치의 주요한 특징은 저장 용량과 읽기/쓰기 속도가 반비례 하는 경향이 있다는 점이다. 저장장치의 종류에는 Cache 메모리, 주기억장치, 보조기억 장치등이 있다.
Cache 메모리는 CPU가 연산을 하기 위해서 접근하는 저장장치로 가장 빠른 속도를 가진다.
주기억장치는 RAM으로 불리고 보조기억장치에서 데이터를 불러들여 Cache에 데이터를 보내는 역할을 한다.보조기억 장치는 컴퓨터의 전원이 꺼진 상태에서도 데이터를 오래 저장할 수 있는 기억장치다.

메모리 계층 구조 1.1.3 통신 계층
앞에서 설명한 연산장치와 기억장치를 연결해주는 BUS들의 변형으로 RAM과 L1/L2Cache를 연결하는 FSB 가 있고, 제일 빠른 속도로 초당 십여Gbit/s를 전송한다.
GPU와 RAM은 PCI로 연결되어있어 통신속도는 GPU의 빠른 연산속도에 방해가 되기도 한다.
네트워크 통신은 초당 수십~백 Mbit/s 로 매우 느리다.
버스의 핵심 속성은 주어진 시간 안에 얼마나 많은 데이터를 전송할 수 있는지를 나타내는 속도다. 이 속성은 한 번에 전송할 수 있는 데이터의 양을 나타내는 버스 폭과 초당 몇 번 전송할 수 있는지를 나타내는 버스 주파수(frequency)로 결정된다. 한 번의 전송으로 데이터를 옮기는 과정은 순차적이다. 버스 폭이 넓으면 필요한 데이터를 한 번에 옮길 수 있으므로 코드를 벡터화할 수 있다. 버스폭이 좁더라도 버스 주파수가 높다면 임의의 메모리 영역을 자주 읽을 때 도움이 된다.
1.2 기본 요소 조합하기

check_prime.py 이 코드는 매 for loop을 돌면서 ram에서 sqrt_number의 요소 i를 L1/L2 Cache로 읽으며 수행이 된다. 이상적으로는 sqrt_number를 한꺼번에 Cache로 보내면 FSB로 통하는 데이터 전송 횟수를 최소화 할 수 있다.
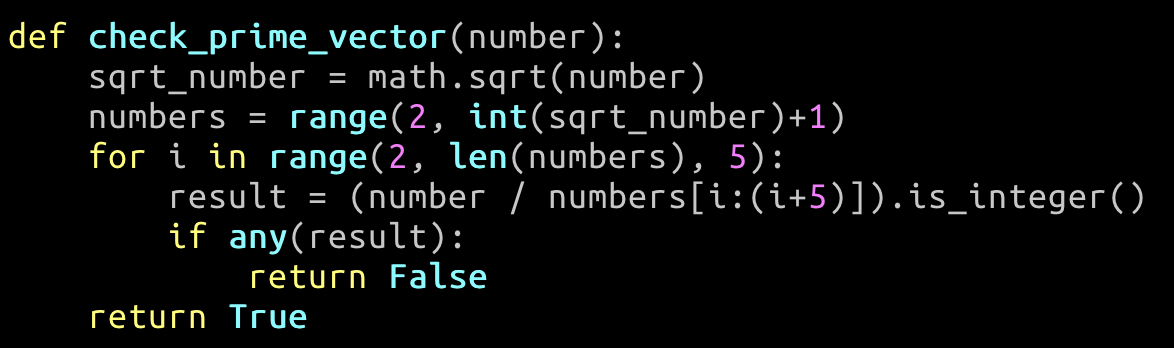
올바른 파이썬 코드가 아니라고 한다... 이 코드를 벡터 계산을 통해 CPU가 한번에 한개의 연산을 하는 것이 아니라, 5개씩 연산을 한다면, 더욱 최적화가 가능하다.
파이썬 가상 머신
파이썬 인터프리터는 컴퓨터의 구성 요소를 추상화해준다. 따라서 배열을 위한 메모리 할당, 메모리 정렬, CPU로 데이터를 보내는 순서 등을 개발자가 고민할 필요가 없다. 이는 구현해야할 알고리즘에만 집중할 수 있게 해주는 파이썬의 장점이지만, 대신 성능상의 비용을 엄청나게지불해야 한다.
건초더미(haystack)에서 바늘(needle)을 찾는 코드가 있다.

reducing_operations.py search_slow 코드는 모든 건초더미를 순회하여 바늘이 있는지를 파악하고, 그 결과를 반환하지만, search_fast는 바늘을 찾는 순간 그 결과를 반환하여 불필요한 계산을 없앤다.

그렇다면 다음의 두 코드 search_unknown1, search_unknown2에서 어떤 연산이 더 빠를지 파악이 가능할까?

reducing_operations.py 파이썬의 파생된 타입, 특별 파이썬 매서드, 서드파티 모듈 등을 다룰때 시간이 얼마나 걸리는지 파악하는것은 매우 어렵다. 따라서 프로파일링을 통해 코드의 느려진 부분을 찾아내고, 더 효율적인 방법으로 처리하는 작업이 필요하다.

파이썬의 추상화는 다음 계산에 사용할 데이터를 L1/L2 Cache에 유지해야하는 최적화에 방해가 된다.
1. 파이썬 객체가 메모리에 최적화된 형태로 저장되지 않기 때문
2. 파이썬이 동적 타입을 사용하며, 컴파일되지 않기 때문. ( Cython을 이용하여 코드에 대한 힌트를 주어 문제를 극복할 수 있다.)
3. GIL때문에 코드를 병렬로 실행할때 성능을 낮춘다. (multiprocessing 등의 방법을 이용해서 회피)
1.3 파이썬을 쓰는 이유
그럼에도 불구하고 파이썬을 쓰는 이유는 표현력이 좋고, 배우기 쉽기 때문에 생산성이 높다.
많은 파이썬 라이브러리는 다른 언어로 작성된 도구를 감싸서 빠르게 수행할 수 있도록 한다.
1.4 뛰어난 성과를 거두는 파이썬 프로그래머가 되는 방법
작동하게 만들라, 제대로 만들라, 빠르게 만들라
-> 프로그램의 구조를 먼저 생각하고 코딩을 시작 -> 테스트 코드를 이용하여 정상적으로 작동하는지 확인 -> 빠르게 수행되도록 모듈 단위를 변경하기
1.4.1 모범적 작업 절차
문서화, 좋은 구조, 테스트가 핵심 요소이다.
README 파일을 작성하라. - 필요하면 나중에 docs/ 폴더를 추가
Docker 사용 권장
tests/ 폴더를 추가하고 단위 테스트를 만들어라 (pytest 추천)
코드의 함수, 클래스 모듈에 독스트링을 추가하면 도움이 된다. (블럭 주석을 이용하여 작동에 대한 내용 기술)
git을 이용하여 소스 관리를 하라
PEP8 스타일의 표준 코딩을 지켜라
자동화 구축해라 (자동 빌드, 자동 테스트, 지속적 통합, 자동 배포 등)
가독성이 중요하다.
1.4.2 주피터 노트북 잘 다루기
시각적인 의사소통에 유용함
긴 함수들은 python module로 추출하고 테스트를 추가하는 편이 좋음
assert 문을 넣어 함수가 생각대로 동작하는지 검증하기 좋음.
데이터를 검증하기 위한 assert는 좋지 않다.
노트북의 끝에 무결성 검사를 추가
1.4.3 일하는 즐거움 되찾기
번아웃에 빠지는것을 막기 위해서 "축하할만한 일의 로그"를 작성하는것이 좋음.
후기
이번 Chapter에서는 1.4.1절이 가장 눈에 띄었다. 빠르게 코드를 작성하기 위하여 동작 위주의 코딩을 많이 했었다. 그러다보니 유지보수하기도 비교적 어려운 것 같고, 뭔가 마음에 들지 않는 코드가 되어있을때가 많이 있었다.
이 부분에서 리펙토링에서 가장 먼저 강조했던 "테스트 코드"를 만들라는 내용도 다시 한번 되새기게 되었고, pylint 등의 라이브러리를 이용하여 범용적으로 쓰는 표현으로 코딩을 하도록 하는것에대해 힌트를 얻을 수 있었다.
'STUDY > 고성능 파이썬' 카테고리의 다른 글
고성능 파이썬 Chapter 05 - 이터레이터와 제너레이터 (1) 2024.12.08 고성능 파이썬 Chapter 04 - 사전과 셋 (0) 2024.12.08 고성능 파이썬 Chapter 03 - 리스트와 튜플 (1) 2024.12.08 고성능 파이썬 Chapter 02 - 프로파일링으로 병목 지점 찾기 (0) 2024.12.01 고성능 파이썬 Chapter 1 실습 (1) 2024.11.28